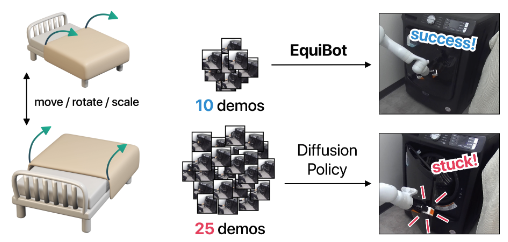
Jingyun Yang
I'm a fourth-year PhD student in the Department of Computer Science at Stanford University. My research focuses on developing generalizable, data-efficient, and deployable methods for robot policy learning. I am advised by Jeannette Bohg as part of the Interactive Perception and Robot Learning Lab.
Previously, I received my Master's degree in Machine Learning at CMU, where I was co-advised by Katerina Fragkiadaki and Christopher G. Atkeson. Before that, I was an undergraduate student at USC, where I worked with Joseph Lim.